Text Tokenization
March 11, 2025
Tokenization is used in natural language processing (NLP) to split paragraphs and sentences into smaller units that can be more easily assigned semantics.
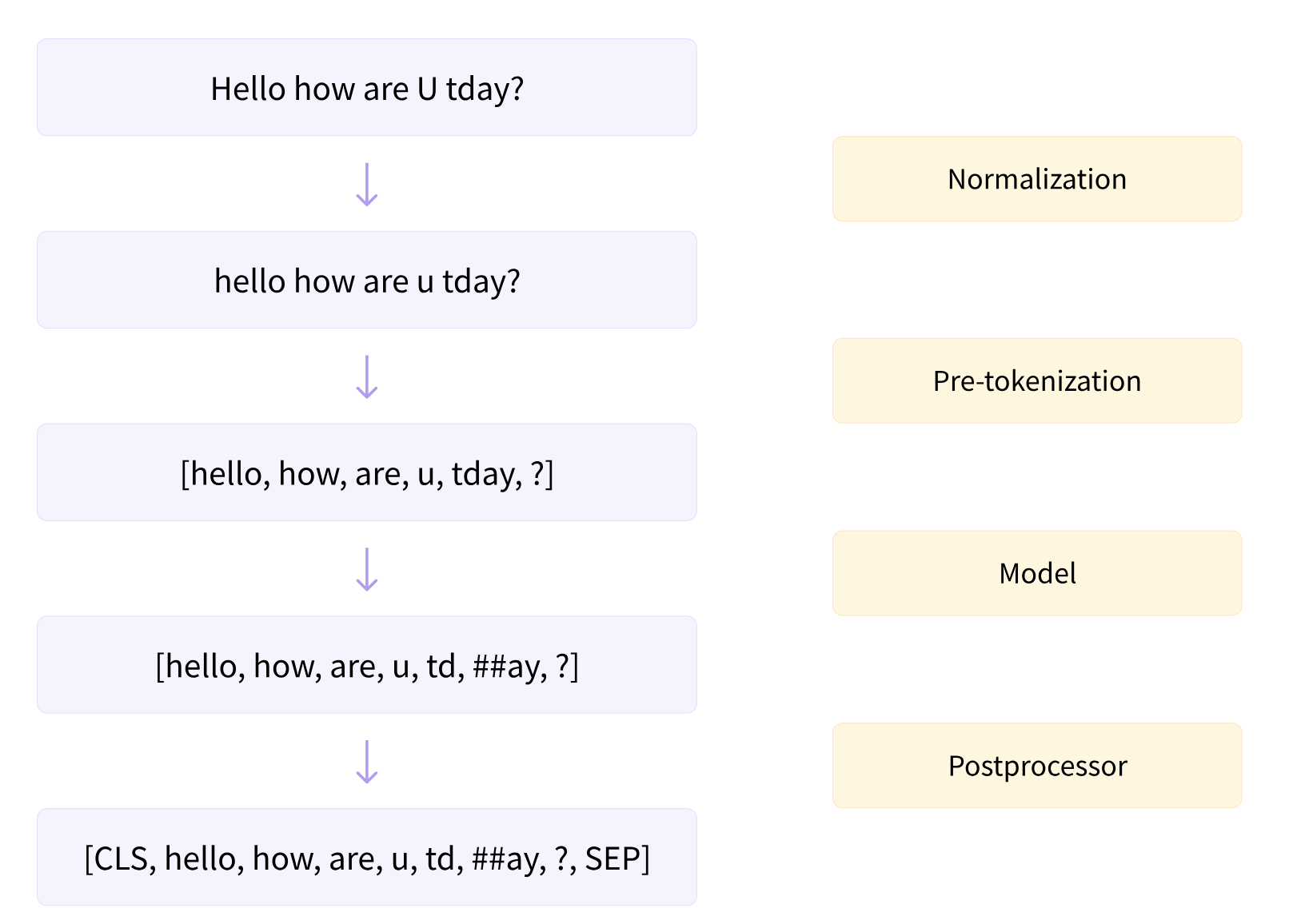
</br>
where model refers to tokenizer model not LLM/transformer.
Post-processor is tokenizer-added special process such as adding [CLS] and [SPE] to the start and end of a sentence.
The general rule is that, exhaustively go through all corpus and find most common combinations of letters/characters/symbols that are believed containing rich semantics.
English Tokenization
In English, tense can provide rich info about action/behavior.
For example, for this sentence “A boy is playing football.”, the word “playing” can be tokenized to two words play and #ing, where the prefix # is used to represent special tokenization by tense.
| Representation | |
|---|---|
| Simple | do/does |
| Present | am, is, are doing |
| have/has done | |
| Past | was, were doing |
| had done | |
| Future | will/shall do |
| am/is/are going to do |
Roots and affixes contain rich semantics.
For example, bidirectional can be split into bi (two-), direction and al (adjective indicator).
Chinese Tokenization
In Chinese, splitting directly by individual Chinese characters is a bad approach. Instead, need Chinese corpus to assist extracting semantic words rather than individual Chinese characters.
Given the below Chinese sentence for example, splitting character by character for “林行止” (this is a person name) into three tokens 林, 行 and 止 that translate to “forest”, “walking” and “stop” can make trouble for next step semantic processing.
談到貿易戰的長遠影響,林行止表示貿易戰促使在中國的工廠搬遷到越南、寮國、印度、台灣甚至是馬來西亞,以避開關稅。
The tokenization should ideally give these results:
談到, 貿易戰, 的, 長遠, 影響, ,, 林行止, 表示, 貿易戰, 促使, 在, 中國, 的, 工廠, 搬遷, 到, 越南, 、, 寮國, 、, 印度, 、, 台灣, 甚至, 是, 馬來西亞, ,, 以, 避開, 關稅 and 。.
WordPiece Tokenization
Wordpiece tokenizer is a type of subword tokenizer that splits words into subword units called wordpieces.
It trains tokenization by word pair combination probability
For example, playing by letter tokenization there is p, l, a, y, i, n, g; after training on texts should see tokenization results play and #ing that are most likely observed letter combinations in corpus.
Wordpiece has special symbols (defined in Hugging Face’s transformers.BertTokenizer):
-
unk_token(string, optional, defaults to[UNK], token_id = 100) – The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this token instead. -
sep_token(string, optional, defaults to[SEP], token_id = 102) – The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences for sequence classification or for a text and a question for question answering. It is also used as the last token of a sequence built with special tokens. -
pad_token(string, optional, defaults to[PAD], token_id = 0) – The token used for padding, for example when batching sequences of different lengths. -
cls_token(string, optional, defaults to[CLS], token_id = 101) – The classifier token which is used when doing sequence classification (classification of the whole sequence instead of per-token classification). It is the first token of the sequence when built with special tokens. -
mask_token(string, optional, defaults to[MASK], token_id = 103) – The token used for masking values. This is the token used when training this model with masked language modeling. This is the token which the model will try to predict.
Wordpiece is used in BERT covering a total of 30522 tokens.
Byte Pair Encoding (BPE) Tokenization
Byte pair encoding (BPE): the most common pair of consecutive bytes of data is replaced with a byte that does not occur in that data. At each iterative step, BPE replaces symbols pair by pair (each substitution only contains two repeated symbols).
BPE in English Vocab Tokenization
Similarly, in NLP tokenization, BPE ensures that the most common words are represented in the vocabulary as a single token while the rare words are broken down into two or more sub-word token.
Letter pairs are hashed until all hash representations combinations are unique.
This is a boy, and that is a toy, and that one is another toy.
First do normalization and pre-tokenization
['this', 'is', 'a', 'boy', 'and', 'that', 'is', 'a', 'toy', 'and', 'that', 'one', 'is', 'another', 'toy']
Count the letter pair combinations, merge letter pairs with occurrences more than once, until all combinations are unique, or having covered the whole pre-token length: \(\begin{matrix} \text{1st round counting} & \text{2nd round counting} & \text{3rd round counting} \\ (\text{t}, \text{h}): 4 & (\text{th}, \text{is}): 1 & (\text{this}): 1 \\ (\text{h}, \text{i}): 1 & (\text{th}, \text{at}): 2 & (\text{that}): 2 \\ (\text{i}, \text{s}): 4 & (\text{is}): 3 & (\text{is}): 2 \\ (\text{a}): 2 & (\text{a}): 2 & (\text{a}): 2 \\ (\text{t}, \text{o}): 2 & (\text{to}, \text{y}): 2 & (\text{toy}): 2 \\ (\text{o}, \text{y}): 3 & (\text{o}, \text{y}): 1 & (\text{o}, \text{y}): 1 \\ (\text{a}, \text{n}): 3 & (\text{an}, \text{d}): 2 & (\text{and}): 2 \\ (\text{n}, \text{d}): 2 & (\text{th}, \text{e}): 1 & (\text{th}, \text{e}): 1 \\ (\text{h}, \text{a}): 2 & \\ (\text{a}, \text{t}): 2 & (\text{at}): 2 \\ (\text{b}, \text{o}): 1 & (\text{b}, \text{o}): 1 & (\text{b}, \text{o}): 1 \\ (\text{o}, \text{n}): 1 & (\text{o}, \text{n}): 1 & (\text{o}, \text{n}): 1 \\ (\text{n}, \text{e}): 1 & (\text{n}, \text{e}): 1 & (\text{n}, \text{e}): 1 \\ (\text{n}, \text{o}): 1 & (\text{n}, \text{o}): 1 & (\text{n}, \text{o}): 1 \\ (\text{o}, \text{t}): 1 & (\text{o}, \text{t}): 1 & (\text{o}, \text{t}): 1 \\ (\text{h}, \text{e}): 1 & (\text{h}, \text{e}): 1 & (\text{h}, \text{e}): 1 \\ (\text{e}, \text{r}): 1 & (\text{e}, \text{r}): 1 & (\text{e}, \text{r}): 1 \\ \end{matrix}\)
The example text sentence is split into this list.
['this', 'that', 'is' 'toy', 'and', 'th', 'e', 'a', 'b', 'o', 'n', 'e', 't', 'h', 'r' ]
- A “Strawberry” demo
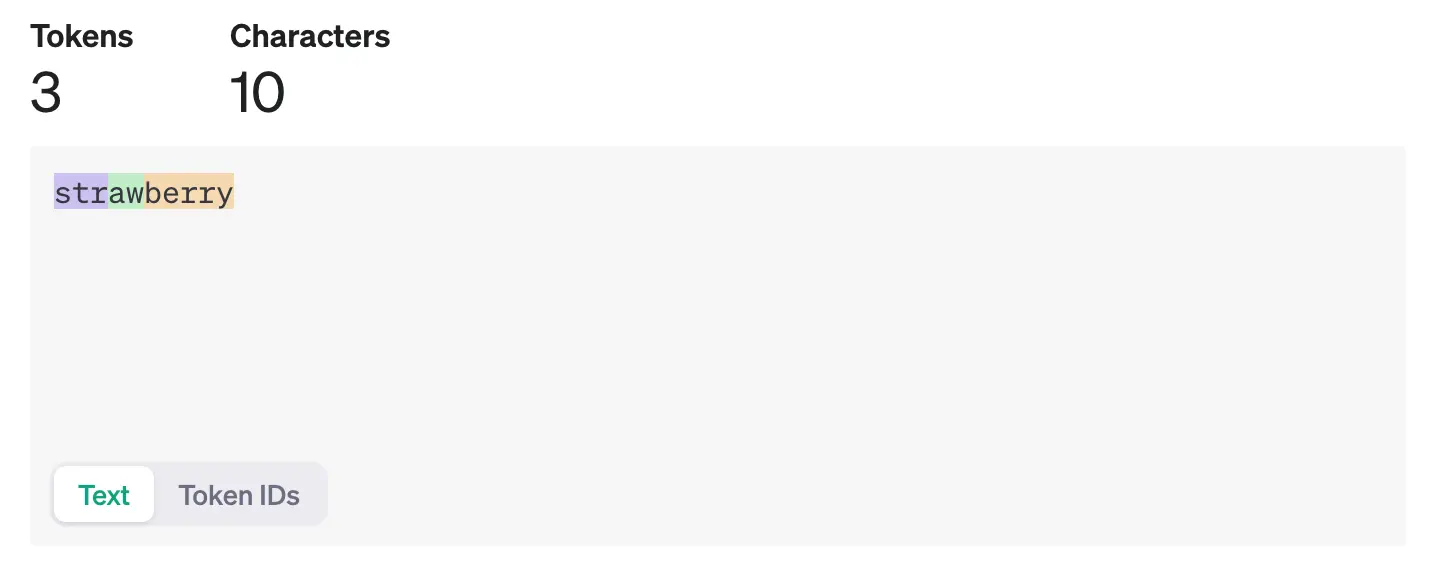
</br>